4 Introduction to causal mediation analysis
In this session we will go over fundamental concepts of causal inference in general and then focus more specifically on causal mediation analysis.
- Explain the theoretical concepts and statistical methods regarding causal mediation analysis
- Perform causal mediation analysis using R software
- Interpret results from causal mediation analysis
4.1 What is a cause?
In a way this can be very intuitive. If I press the switch, the light will come on. We use causal reasoning all the time. If I do A, then Y will happen. Some relationships we can define them to be deterministic. Doing A will always lead to Y. This is useful for our intuition but when we work with health outcomes it is more complicated.
A = received treatment/intervention/exposure (e.g., 1 = intervention, 0 = no intervention)
Y = observed outcome (e.g., 1 = developed the outcome, 0 = no outcome)
\(Y^{a=1}\) = Counterfactual outcome under treatment a (i.e., the outcome had everyone, counter to the fact, received treatment a = 1)
\(Y^{a=0}\) = Counterfactual outcome under treatment a (i.e., the outcome had everyone, counter to the fact, received treatment a = 0)
4.1.1 Individual causal effect
When investigating health outcomes, we would ideally want to know if you do X, then Y will happen. We could have a specific question:
Will eating more red meat give me higher blood glucose in 1 year?
To answer this question we would ideally have you consume more red meat over 1 year and measure your blood glucose levels. Then, we would turn back time, and make you eat something else over 1 year and then measure your blood glucose levels again. If there is a difference between your two outcomes, then we say there is a causal effect.
But we can never do this in the real world.
4.1.2 Average causal effect
Instead, we can perform a randomized controlled trial. We now ask a slightly different question:
Will eating more red meat give adults higher blood glucose in 1 year?
We can randomely assigning one group to consume more red meat and the other group to consume more of something else over 1 year. Then we compare the average blood glucose levels after 1 year in each of the groups. If there is a difference, we could say there is an average causal effect.
We now modify the terms a little.
\(E[Y^{a=1}]\) the average counterfactual outcome, had all subjects in the population received treatment a = 1.
\(Pr[Y^{a=1}]\) the proportion of subjects that would have developed the outcome Y had all subjects in the population of interest received treatment a = 1.
4.1.3 Definition of a causal effect
More formally we can now define a causal effect (1):
\(E[Y^{a=1} = 1] - E[Y^{a=0} = 1] \ne 0\)
4.1.4 Code example: estimating causal effect
To get an idea of what is going on, we will simulate a simple dataset with an outcome Y, treatment A and a confounder W.
Then, we will run a linear regression model for the effect of the treatment on the outcome, adjusting for confounder w.
We now use this model to predict the outcome, if all had received treatment = 1 and another prediction of the outcome had everyone not received treatment (A = 0).
We can now get the causal effect, which is the average of the difference in the treatment effect in each group. Or put more formally \(E[Y^{a=1} = 1] - E[Y^{a=0} = 1]\)
It turns out that this average causal effect is the same as the regression coefficient in the linear model.
#>
#> Call:
#> lm(formula = y ~ a + w)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -5.1258 -0.6755 0.0013 0.6750 4.8683
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) -0.0012399 0.0014143 -0.877 0.381
#> a 1.0019699 0.0019992 501.186 <2e-16 ***
#> w 0.9987072 0.0009991 999.646 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.9996 on 999997 degrees of freedom
#> Multiple R-squared: 0.5556, Adjusted R-squared: 0.5556
#> F-statistic: 6.251e+05 on 2 and 999997 DF, p-value: < 2.2e-16A regression-based approach can in some situations also be used. However, for more complicated situations, the regression-based approach fail. The causal intuition in the regression-based approach is also less clear.
Why is there no difference between the linear regression coefficient and the predicted mean difference?
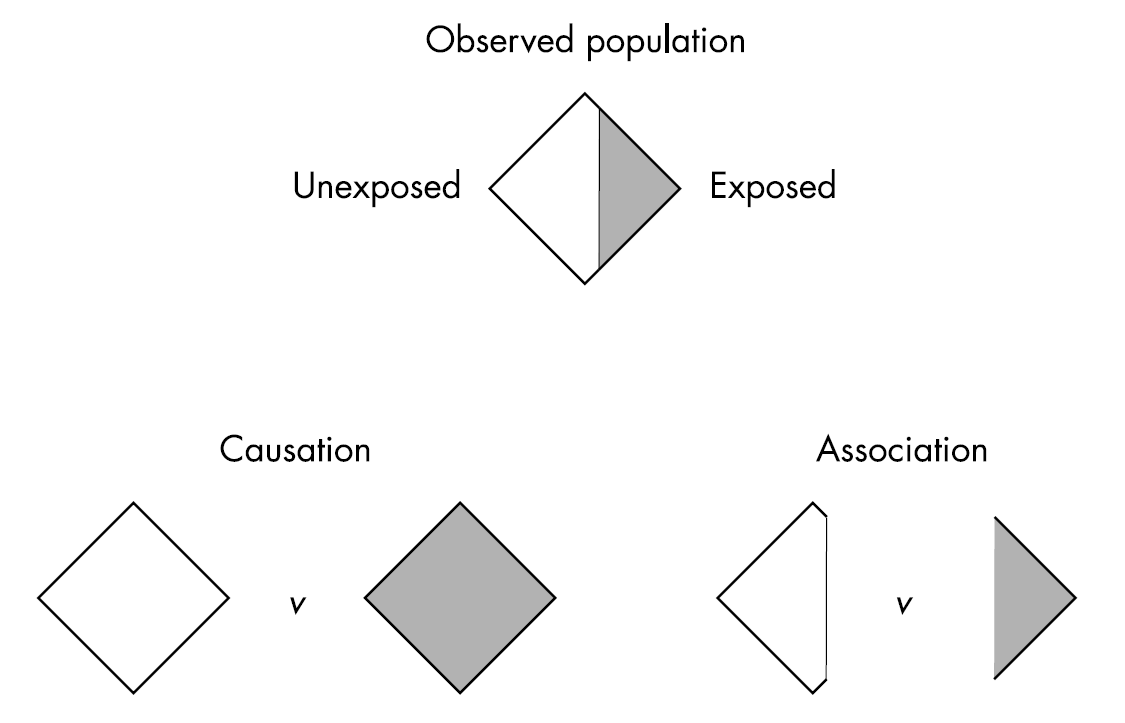
4.2 Association vs causation
What makes it complicated to estimate a causal effect is that we cannot observe the outcome under different treatments.
When we only have a subset of the outcomes, we have an association. This is illustrated in Figure 4.1.
If we want to infer a causal effect (i.e., what would have happened, had everyone done A=1 vs A=0), we need three assumptions to be fulfilled:
- Exchangeability
- Consistency
- Positivity
4.2.1 Exchangeability
The risk of the outcome in A = 1 would have been the same as the risk of the outcome in A = 0, had those in A = 1 received A = 0.
Think about a randomized trial where you, by mistake, give the intervention to the other group. The effect should be the same as the one you would have observed had the groups been correct.
We can also have conditional exchangeability. The risk is similar in subsets of the population. That could be within the levels of a variable W (e.g., education).
4.2.2 Consistency
The treatments under comparison are well-defined and correspond to the versions of treatment observed in the data:
- Precise definition of \(Y^a\) via a
- Link counterfactual outcomes with observed outcomes
\(Y^a = Y\) for every individual with A = a.
The observed outcome for all treated equals the outcome if they had received the treatment.
4.2.3 Positivity
The probability of receiving every value of treatment conditional on L is greater than zero. In other words, there must be a probability of being assigned to each treatment level.
Think, if we don’t have anyone with A = 0 among those with L=1 (e.g. long education), then we cannot estimate the conditional probability of the outcome.
4.3 A randomized controlled trial
In a randomized controlled trial these assumptions are often fulfilled given that the randomization is successful (i.e., have exchangeability and large enough groups), the treatment is clearly defined (consistency) and by design all have the possibility to be in either group (positivity).
These assumptions are much harder, let alone impossible, to verify in an observational study. That is why causation is more challenging in observational studies.
4.4 Importance of good research questions
When we talk about causal effects, we often ask “what if”-questions and we can think of them in the context of a randomized controlled trial.
A formal extension of this notion is the target trial framework. Here, one first specify the target trial, or referred to as the hypothetical interventions that one would have wanted to perform, to address a specific research question.
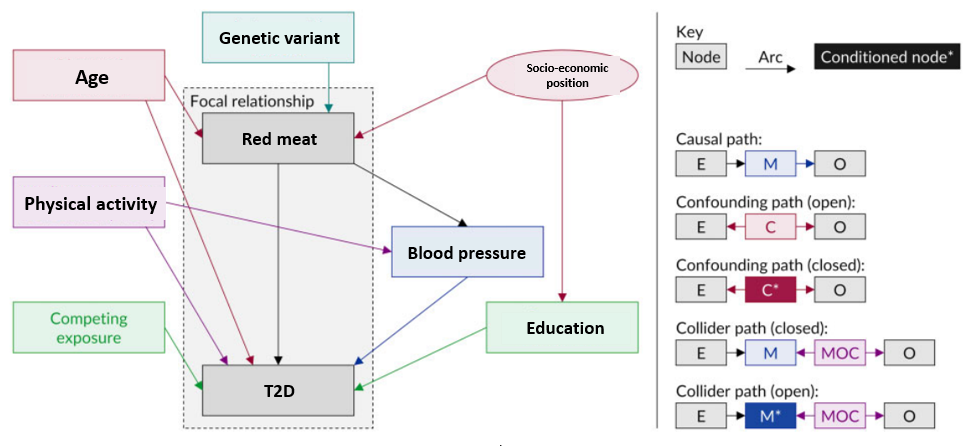
4.5 Directed Acyclic Graphs
Another method to graphically display your research question and your assumptions about your data is by using directed acyclic graphs (DAGs). DAGs are a simple and transparent way to identify and illustrate your assumptions about the causal relationships between variables in your dataset.
A DAG contains nodes and arrows. It cannot be circular. Figure 4.2 shows the different types of variables in a DAG and rules for paths (2).
4.6 Causal mediation analysis
Causal mediation analyses help you establish whether treatment causes the outcome because it causes the mediator. To do this, causal mediation seek to understand how the paths behave under circumstances different from the observed circumstances (e.g., interventions).
Causal mediation analysis is an extension of the traditional approach by:
- outlining all confounding assumptions needed
- handling non-linearity and interaction
- clearly defining estimands of interest
4.7 Confounding assumptions
By using DAGs, the assumptions about confounding are made much more explicit.
DAG under no mediator-outcome relation affected by treatment:
We can see that we not only have to take confounding between the treatment and outcome into account, but we also have to take mediator-outcome (\(A \leftarrow W \rightarrow Y\)) confounding into account.
Note, even if you have a randomized controlled trial, you can have mediator-outcome confounding. This is because the mediator has not been randomized.
Consequently, mediation analysis in randomized controlled trials also need to do adjustment of potential confounders and residual confounding cannot be ruled out.
In addition, we can have a more complicated situation where the treatment also impacts another mediator that is also a mediator-outcome confounder.
DAG where the mediator-outcome relation is affected by treatment:
From the DAG rules, we have a special problem that we cannot solve with traditional regression approaches. If we adjust for W2 we open a backdoor path by adjusting for the collider \(W1 \rightarrow W2 \leftarrow A\). We will work on how to solve this problem later in the course.
4.8 Non-linearity and interactions
Neither the product method nor the difference method can take interaction and non-linearity into account.
Causal mediation analysis can take this into account. It can do this using a regression-based approach. It can also use other causal inference analysis methods such as g-computation, that are different from the traditional regression approach in that:
- it builds a causal model. This model can include non-linearity and interactions
- then artificially manipulate the data to set the treatment and the mediator to certain values
- then predict the outcome using the causal model and contrast the outcomes
Additional approaches also exists, but we will not focus on these in this course.
4.9 Defining estimands
Imagine we have a hypothetical randomized controlled trial where we give participants treatment or no treatment on a specific outcome Y.
\(Y^{a=1} - Y^{a=0}\)
For mediation, we are also interested in the effect of a mediator on this pathway. Now image that we also intervene on the mediator in a new hypothetical randomized controlled trial.
\(Y^{m=1} - Y^{m=0}\)
Now consider if we, in the same trial, could intervene on both because we are interested in whether treatment causes the outcome because it causes the mediator.
\(Y^a\) = a subject’s outcome if treatment A were set, possible contrary to fact, to a
\(M^a\) = a subject’s value of the mediator if the exposure A were set to the value of a
\(Y^{a,m}\) = a subject’s outcome if A were set to a and M were set to m
\(Y^{a,M_a}\) = a subject’s outcome if A were set to a and M were set the value m would have had had a been set to a. Note, this is a nested counterfactual
We can now define these estimands:
- the controlled direct effect (CDE)
- natural direct effect (NDE)
- natural indirect effect (NIE)
4.9.1 Controlled direct effect
The effect of A on Y not mediated through M. Fixing the value of M to m.
\(Y^{a=1,m}\) - \(Y^{a=0,m}\)
We intervene on \(a\) but fix \(m\) to a certain value. The CDE is how much the outcome would change on average if the mediator were fixed at level m uniformly in the population but the treatment were changed from 0 to 1.
This could be relevant in the context of a change in a policy that impacted the mediator for everyone. For instance, if air pollution was a mediator between physical activity and cardiovascular disease risk. If a new policy would change the level of air pollution for all while we implement an intervention to increase biking in the city.
This effect is not used that often. But can be highly relevant in some situations.
4.9.2 (Pure) Natural direct effect
The effect that would remain, if we were to disable the pathway from exposure to mediator.
\(Y^{a=1,M_a=0}\) - \(Y^{a=0,M_a=0}\)
The PNDE is how much the outcome would change if the exposure was set at a = 1 versus a* = 0 but for each individual the mediator was kept at the level it would have taken, for that individual, in the absence of the exposure.
Note that the word “natural” refers to the nested counterfactual, the level the mediator would have taken in the absence of exposure. What it would naturally have been in the absence of exposure.
4.9.3 Total natural direct effect
\(Y^{a=1,M_a=1}\) - \(Y^{a=0,M_a=1}\)
Note, different from above in that the mediator is kept at the level it would have taken in the presence of the exposure.
4.9.4 (Total) Natural indirect effect
The effect of the mediator pathway.
\(Y^{a=1,M_a=1}\) - \(Y^{a=1,M_a=0}\)
The NIE is how much the outcome would change on average if the exposure were fixed at level a = 1 but the mediator were changed from the level it would take if a* = 0 to the level it would take if a = 1.
Note that exposure has to have an effect on M otherwise this will be zero.
4.9.5 Pure natural indirect effect
\(Y^{a=0,M_a=1}\) - \(Y^{a=0,M_a=0}\)
Note, this is different from the TNIE in that the exposure is set to no intervention.
4.9.6 Interaction effects
More information on the interaction effects can be found in (3).
Reference interaction:
\(INT_{ref} = PNDE - CDE\)
Mediation interaction:
\(INT_{med} = TNIE - PNIE\)
4.9.7 Effect decomposition
Using the causal inference framework also allow for effect decomposition, even when there are interaction and non-linearity.
Effect decomposition is important when we want to assess relative contributions such as the proportion mediated and eliminated.
TE = PNDE + TNIE = TNDE + PNIE
More information about decomposition of effects can be found in (3).
4.9.8 Proportions
Proportion CDE:
\(prop^{CDE} = CDE / TE\)
Proportion \(INT_{ref}\)
\(prop^{INT_{ref}} = INT_{ref} / TE\)
Proportion \(INT_{med}\)
\(prop^{INT_{med}} = INT_{med} / TE\)
Proportion pure natural indirect effect:
\(prop^{PNIE} = PNIE / TE\)
Proportion mediated:
\(PM = TNIE / TE\)
Proportion attributable to interaction:
\(INT = (INT_{ref} + INT_{med}) / TE\)
Proportion eliminated:
\(PE = (INT_{ref} + INT_{med} + PNIE) / TE\)
4.10 Study designs for causal mediation analysis
Mediation analysis can be used in both intervention and observational studies.
A key assumption is that the exposure should be before the mediator and the mediator and exposure before the outcome. It is possible by design to have these three variables measured at different time points. In practice, this is rarely the case. Probably because the study was not designed to conduct mediation analysis.
Stay in the same groups that you did the previous exercise.
- First discuss the study you were assigned to in the previous session: (10 min)
- How does the study separate the timing between the exposure, mediator and outcome?
- Did the study account for all the confounding assumptions? If not, why not? What could they have done?
- Everyone: (10 min)
- Describe the issues in your study to everyone.
- Everyone: (5 min)
- How should we rank the different studies?
- And what would be the ideal study design?
4.11 Two trials
It is possible to conduct two randomized controlled trials to investigate mediation ((4)). One approach is the so-called parallel design. Two randomized controlled trials are conducted in parallel. The first investigates the effect of the treatment on the outcome (i.e., total effect). In the second trial we randomize both the treatment and the mediator.
For example, one could use transcranial magnetic stimulation (TMS) to investigate if activation of specific brain regions mediate the propensity to accept more unfair monetary offers in a bidding game called the “ultimatum game” ((5)). First, you conduct an experiment with unfair bidding and acceptance. Then one conducts the same experiment but with manipulation of the mediator, here TMS to activate a certain brain region.
A key assumption here is consistency. The subjects should not know the receive the extra intervention.
There is also a crossover version ((4)). Here, we first randomize the order of the treatment and control, then observe the effect on mediator and outcome. Then we assign the opposite treatment status and to the value of the mediator that was observed in the first period.
In addition to consistency there is the assumption of no carry-over effects.